Fast data vs Slow data - an Interview with Clifford Chance
Sarah Langton is Global Head of Recruitment at Clifford Chance. We had the chance to sit down with her to discuss a fascinating topic: Two different types of data when it comes to recruiting: Fast data and slow data.
Read (or listen) why this distinction matters.
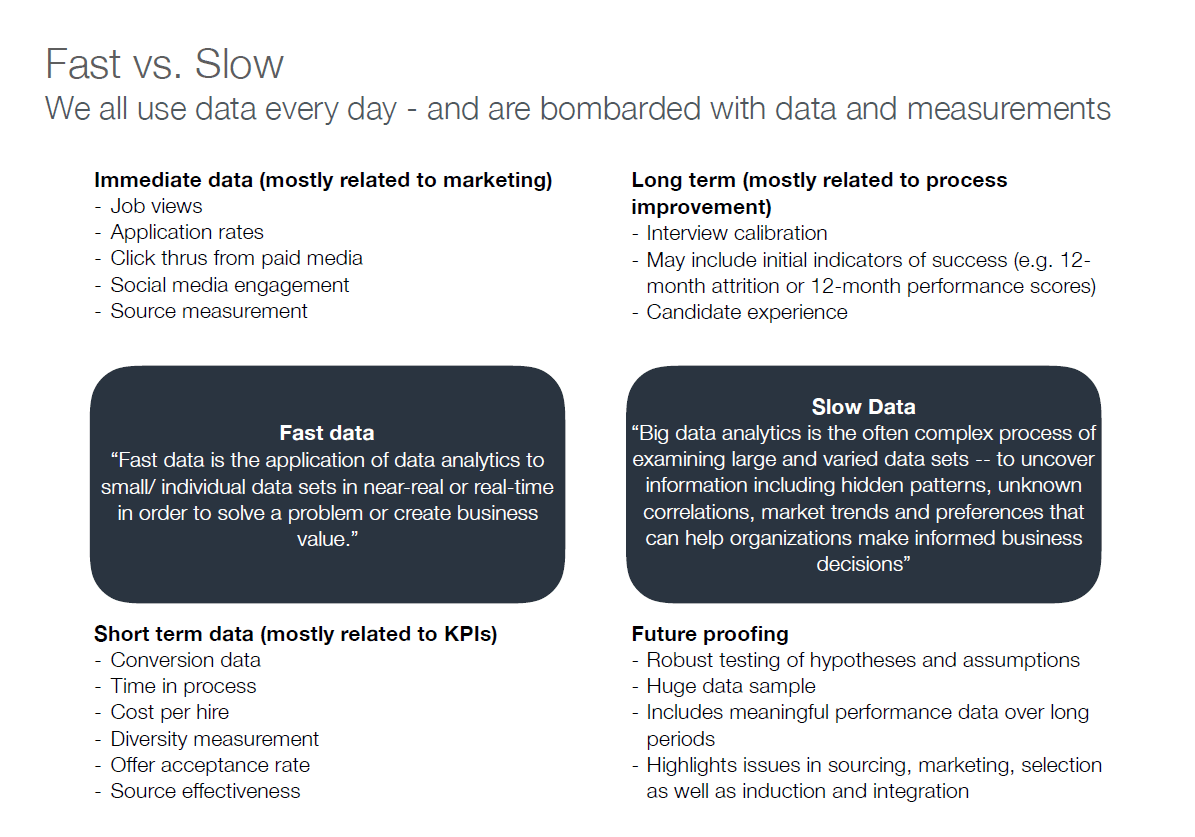
Fast data (FD) is marketing data: Click-through rates on job adverts, social media engagement, application to interview rate, cost per hire etc. It’s readily available and many recruiters regard it as the be-all and end-all of talent acquisition data.
80% of data recruiters have falls in this bucket.
Slow data (SD) is much trickier to gather and analyse: It tells you, after 1-2 (sometimes even more) years if the people you hired with campaign X or initiative Y have performed well and what that tells you about campaign X or initiative Y. You start improving your process as data about attrition and retention rolls in. This data mostly relates to and will help you with process improvement.
Why is it called Slow Data? Because it takes a long time to collect and to derive meaningful insights from. It can be tricky to separate causation from correlation in multivariate data sets: Was it the source of candidates that led to better retention or the new onboarding process we developed? You need a long period of time to collect and analyse it.
Fast data alone doesn’t measure the quality of your recruitment process.
It measures your ability to attract candidates. That’s a crucial distinction. Because the recruitment process is much broader than that: it’s about how the candidates you attract turn out to be adding value to the firm.
This is not to disparage fast data.
It is important to complement SD with FD. Often, FD is the only data available and it can serve as a useful gauge for how you are doing. We often don’t have the luxury of being able to wait for the emergence of slow data to collect feedback.
“Which Slow Data has proven the most useful to you at Clifford Chance?”
The actual performance data of the person we’ve hired, but over a long period of time, not just the first few quarters. And then we look at that against the recruitment process. Extract what are the commonalities and traits of the successful employees, and use that in your recruitment process. Of course, everything on an aggregated and anonymised basis.
That’s the holy grail of proving that your recruitment process is right. It’s not just about your offer-to-acceptance ratio and whether the person is still around 12 months later. But it’s about how successful someone will be when they’re with us for 3 years.
“What would you do if you were dropped into a new company that only uses Fast Data? How would you start improving their processes to develop Slow Data capabilities?”
-
Understand what data you have, what are the sources and where is it kept.
-
Look at it briefly, high level: What’s retention / attrition like? Are there surveys that indicate employee satisfaction and recruitment experience?
-
Identify which Slow Data is missing.
-
Start recording the missing Slow Data in a systematic way.
-
Wait until enough data has accumulated to derive enough material for systematic analysis.
“When we talk about ‘Big Data’ - which data bucket does that fall into?”
Definitely into the Slow Data bucket. Big Data is from multiple sources and it takes a long time to figure out patterns and derive meaning. Fast data, in turn, is much more about one single thing from one source that tells you one reliable metric, but without the wider context.
“What roles does GDPR play in all this?”
You always need to work with a data privacy specialist, that’s clear. There’s a lot of sensitive data you’re handling here. One thing to always keep in mind is to extract the lessons (again: on an aggregate, anonymised level) in time before the data has to be discarded. So it forces you into a regular process because you know the data will only be around for so long.
“What are the main lessons learned for Clifford Chance?”
It’s the insight that fast data isn’t the whole picture. We don’t want to be falling into the trap of only drawing on the majority of data available (which is the fast type) and conclude, for example: “Oh, we got so many applications from this or that recruiting initiative, we must be really good at recruiting.”
One of the benefits of being aware of slow data is that you become somewhat immune to the fascination that fast data may hold. You realise it’s not the whole story.
“How can people learn more?”
I’m always happy to connect with anyone in my field who wants to share their experiences with recruitment and data. Simply add me on LinkedIn or email me at Sarah.langton@cliffordchance.com and let’s talk.
Stay up-to-date with the latest market insights and law firm rankings
Subscribe to email updates
Subscribe to content


