Guides and Tutorials
Get the most from Pirical On Demand & Pirical Legal Professionals
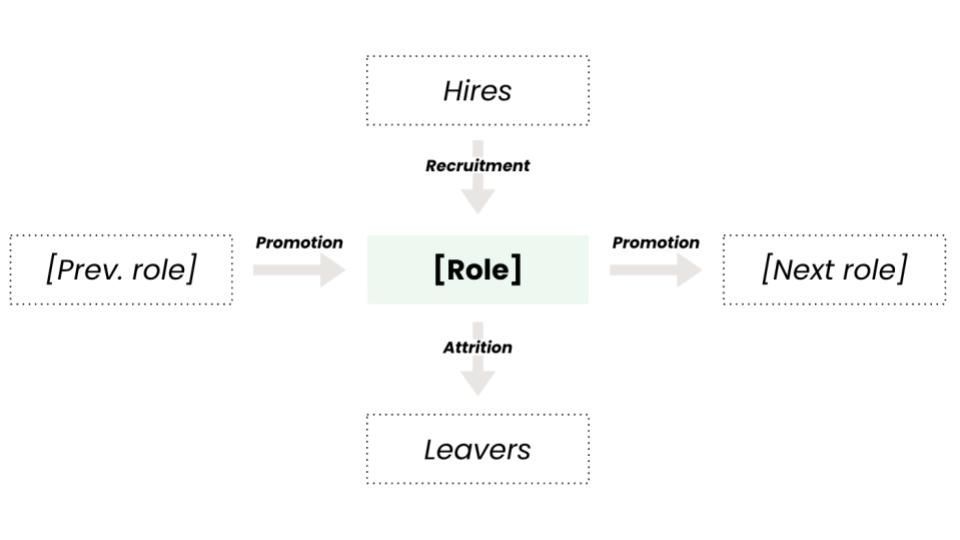
How can you make predictions about the future diversity of your organization, with a model grounded in real data? In this tutorial we will explain how diversity projections work in Pirical On Demand (POD).
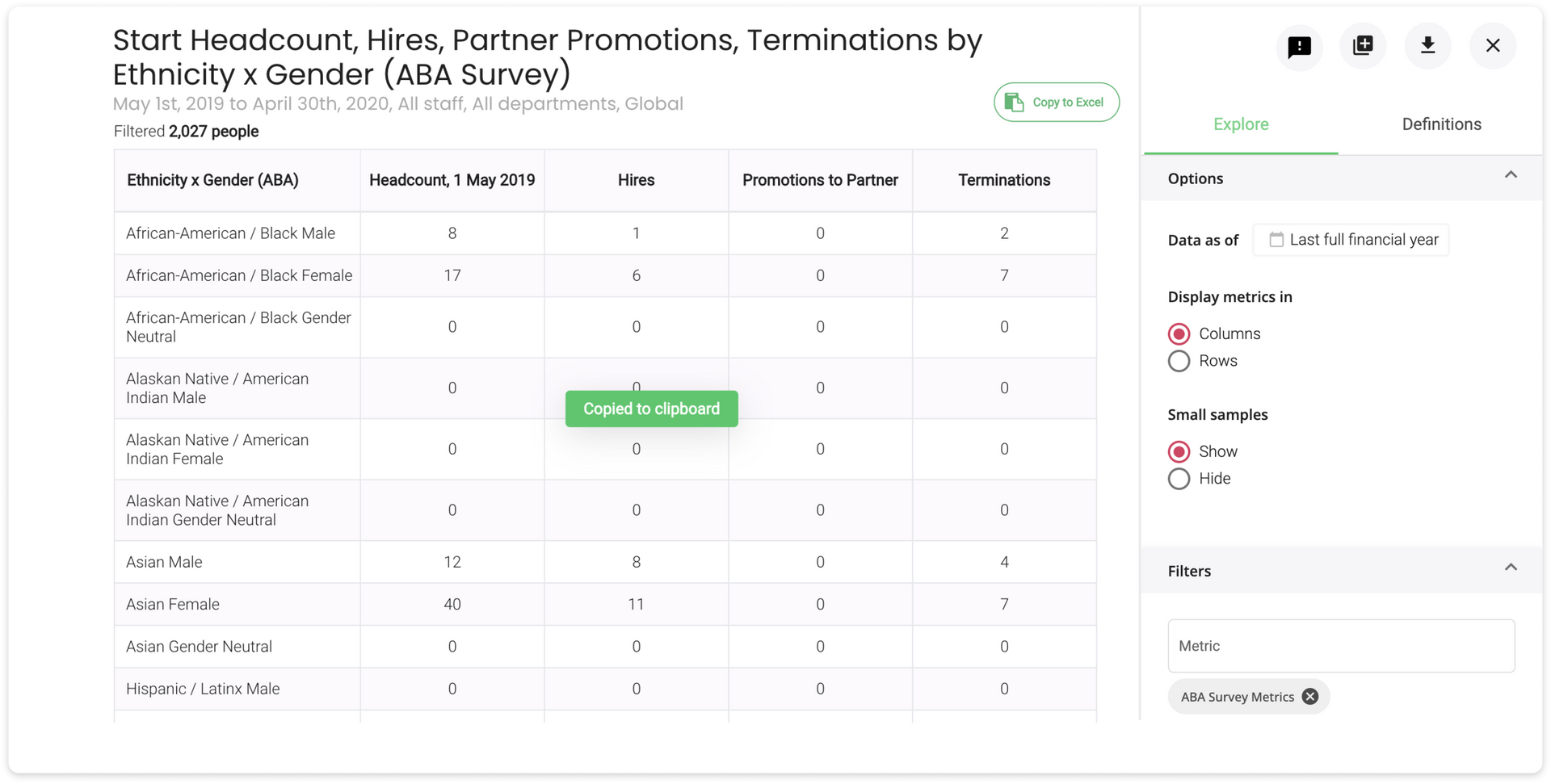
Law firms are spending an increasing amount of time reporting their diversity data to clients and third parties including regulators. Learn how Survey Filler in Pirical On Demand (POD) can save you 90% of the time spent reporting diversity data.
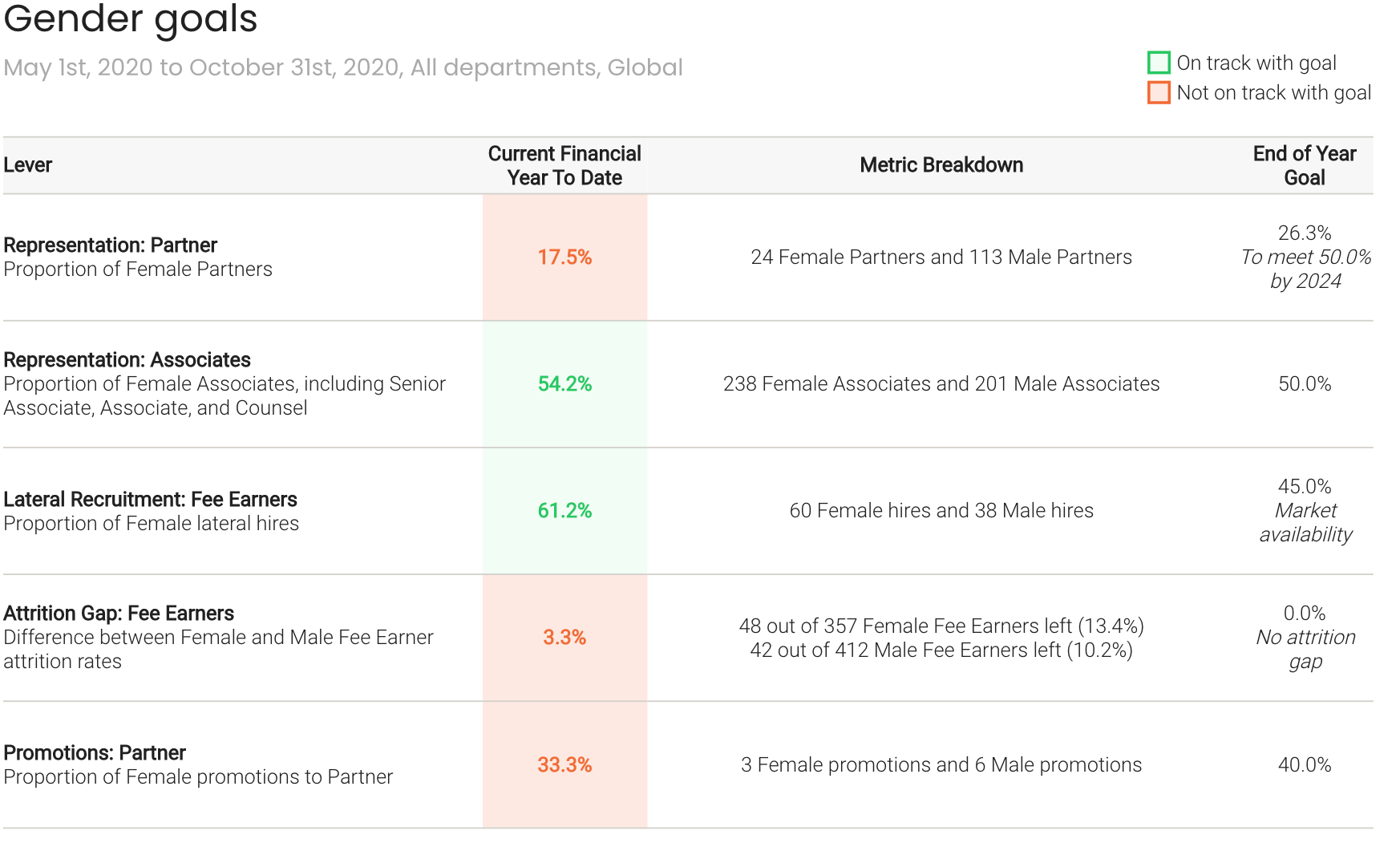
This is a step by step guide about how to set diversity goals using POD.
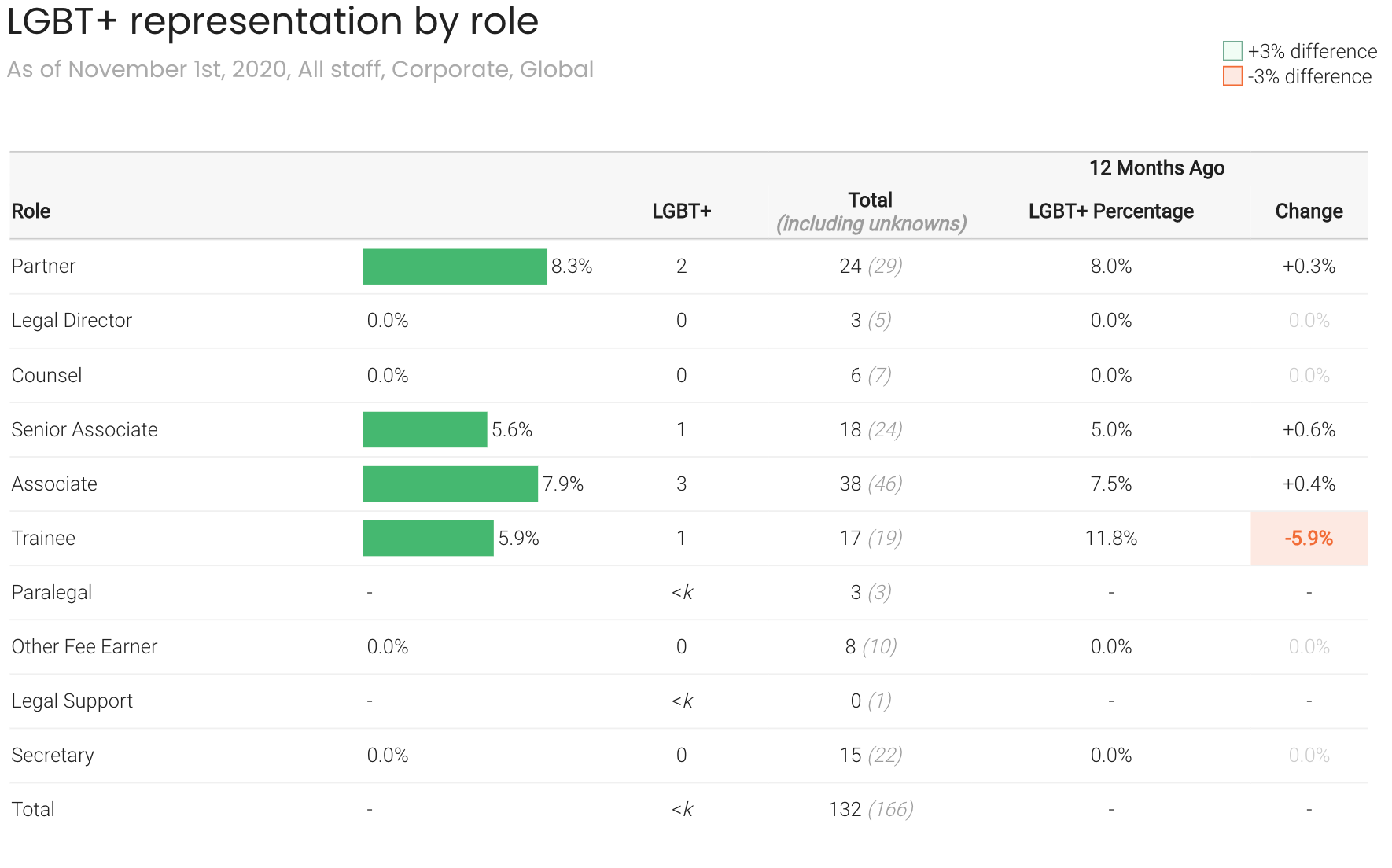
Diversity data is sensitive and individuals need to be protected from inferential disclosure.
When a headcount is below an agreed threshold, k, then the headcount will be hidden.
This prevents accidental disclosure of an individual's private diversity data.
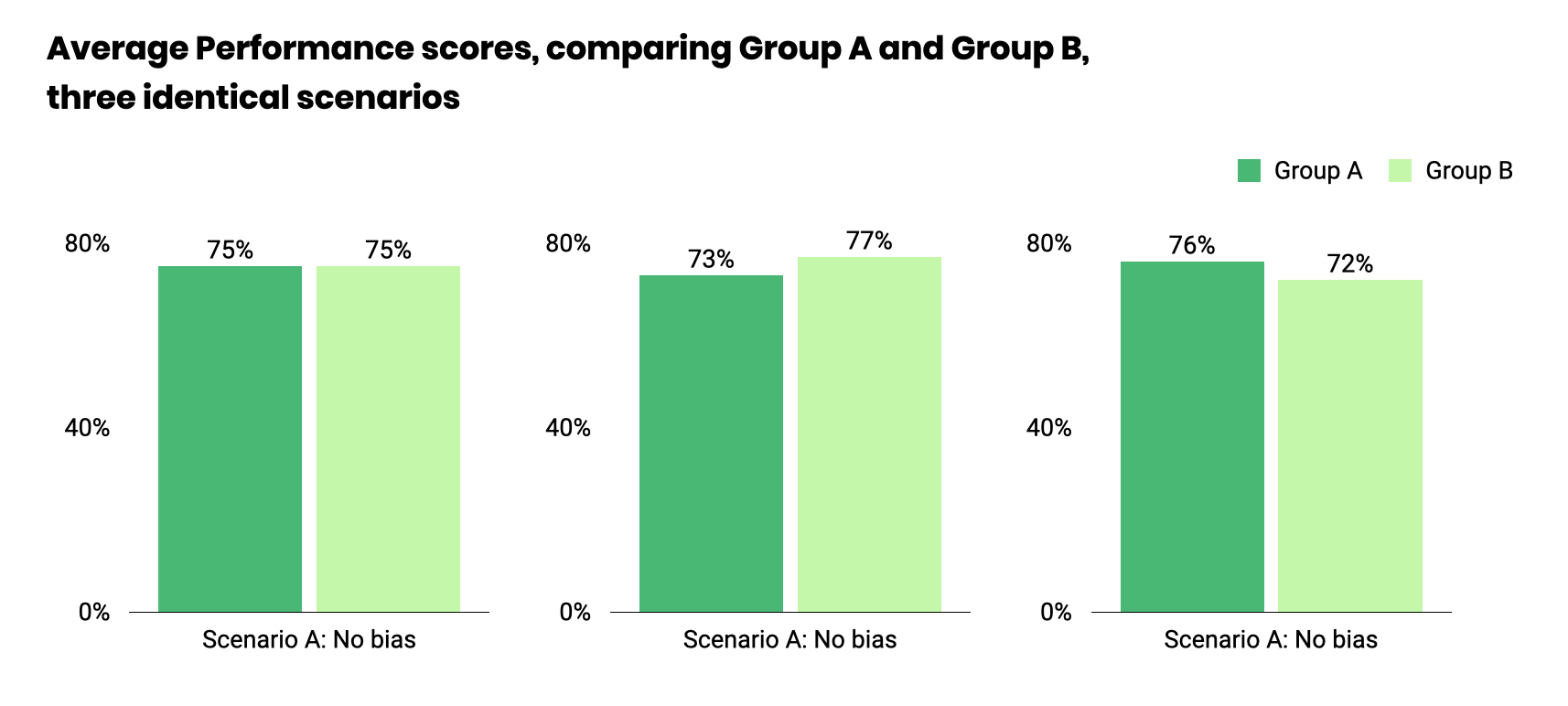
Often featured in our analysis, p-values are statistical measures that allow us to assess, and demonstrate, the significance of our results. To better understand what these values represent, we have put together this quick guide.
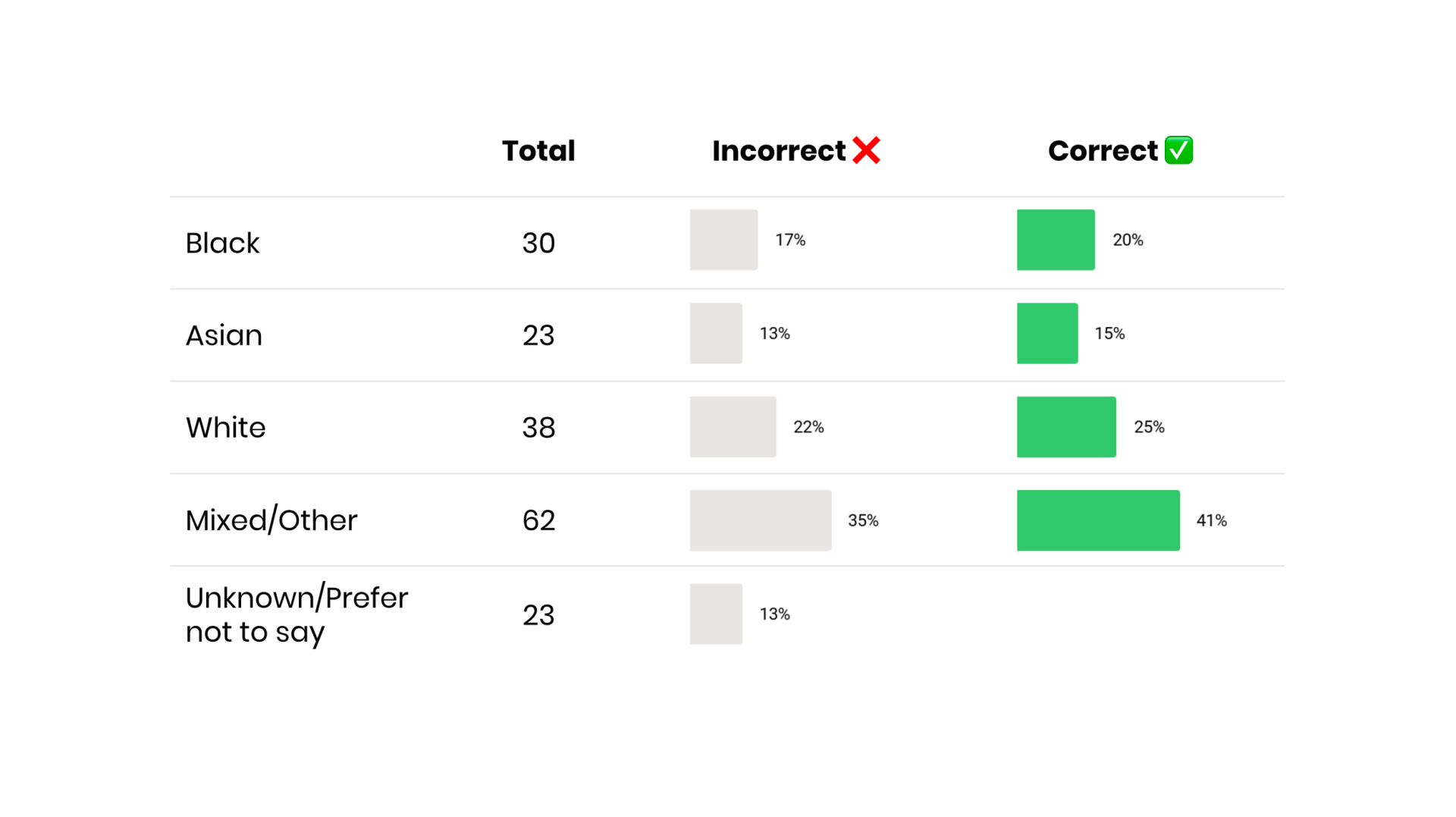
When analysing or reporting on diversity data, two cases are important to
consider:
* individuals who haven’t been asked or did not respond -> Unknown
* individuals who decided not to participate -> Prefer Not To Say (PNS)
A common confusion is how to analyse these records.
As more users have access to self-serve from your firm’s HR data, how can
you make sure commercially or personally sensitive data is protected? In
this tutorial we will explain the privileging system in Pirical On Demand
(POD).
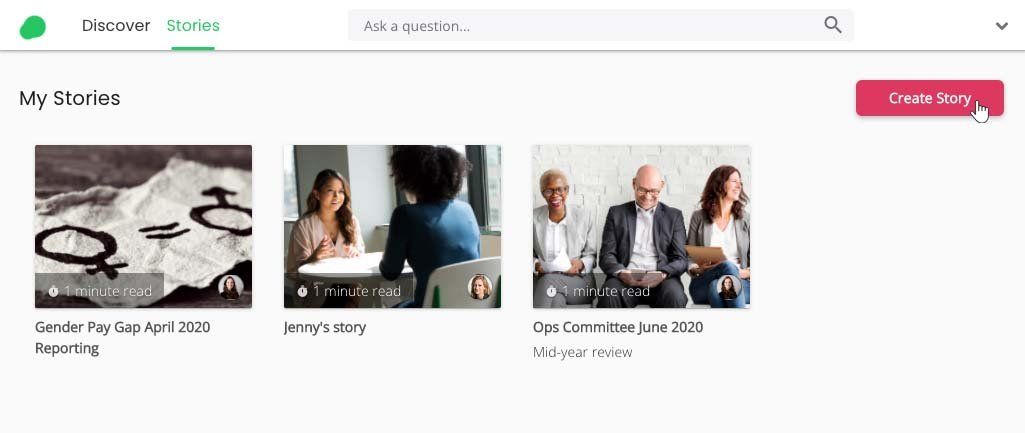
Creating simple, beautiful, and insightful analytics from HR data can be
hard work. Particularly if you want to keep those analyses up to date and
circulate them to stakeholders each month.
In this guide we will look at how to use Pirical On Demand (POD) to
assemble custom stories, which are then automatically kept up to date with
your firm’s latest data.